Publications
Here’s a complete list of the papers I have had the fortune to work on over the years. For the most up-to-date list please visit my Google Scholar page
2025
-
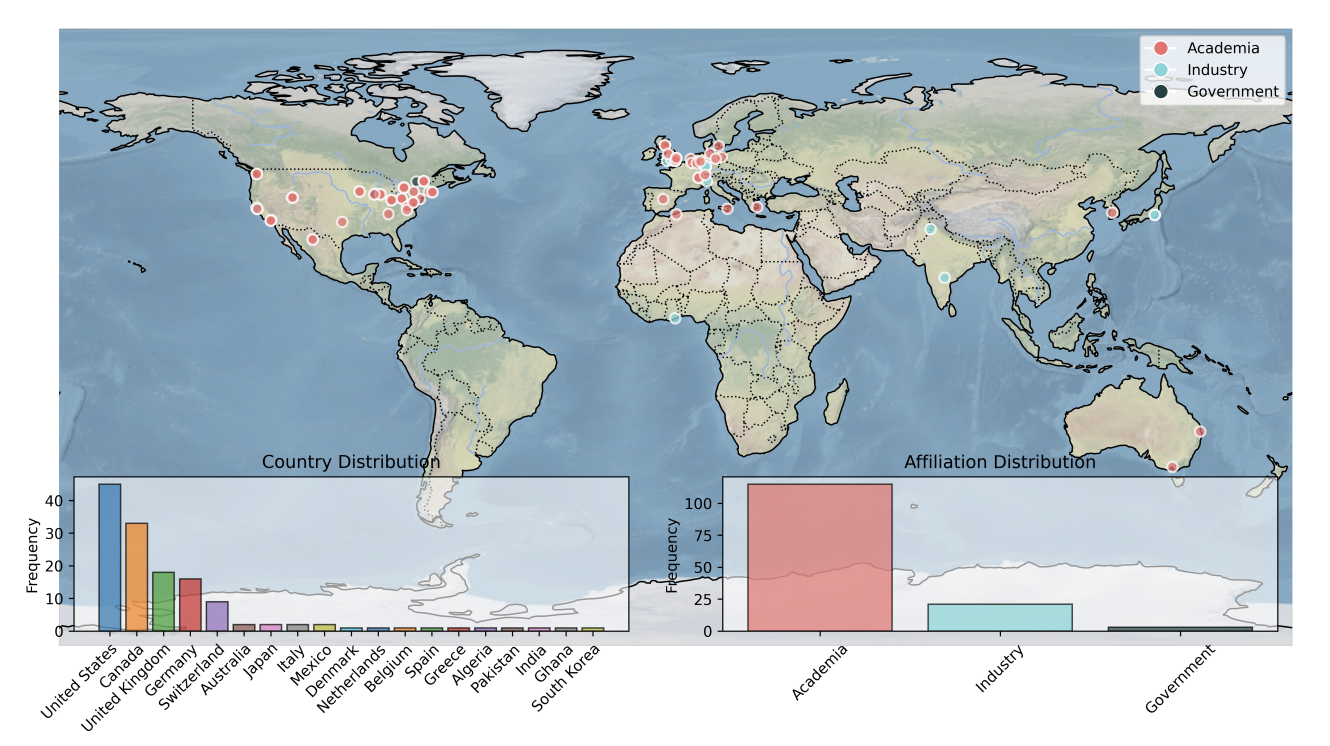 Bayesian Optimization Hackathon for Chemistry and MaterialsSterling Baird, Mehrad Ansari, Zartashia Afzal, and 8 more authorsChemRxiv, 2025
Bayesian Optimization Hackathon for Chemistry and MaterialsSterling Baird, Mehrad Ansari, Zartashia Afzal, and 8 more authorsChemRxiv, 2025@article{2025_Baird, title = {Bayesian Optimization Hackathon for Chemistry and Materials}, author = {Baird, Sterling and Ansari, Mehrad and Afzal, Zartashia and Ai, Qianxiang and Al-Feghali, Alexander and Alain, Mathieu and Altamirano, Matias and Andrews, Thomas and Anker, Andy Sode and Ansari, Rija and others}, year = {2025}, journal = {ChemRxiv}, url = {https://chemrxiv.org/engage/chemrxiv/article-details/684a100a1a8f9bdab5a80a26}, dimensions = {true}, } -
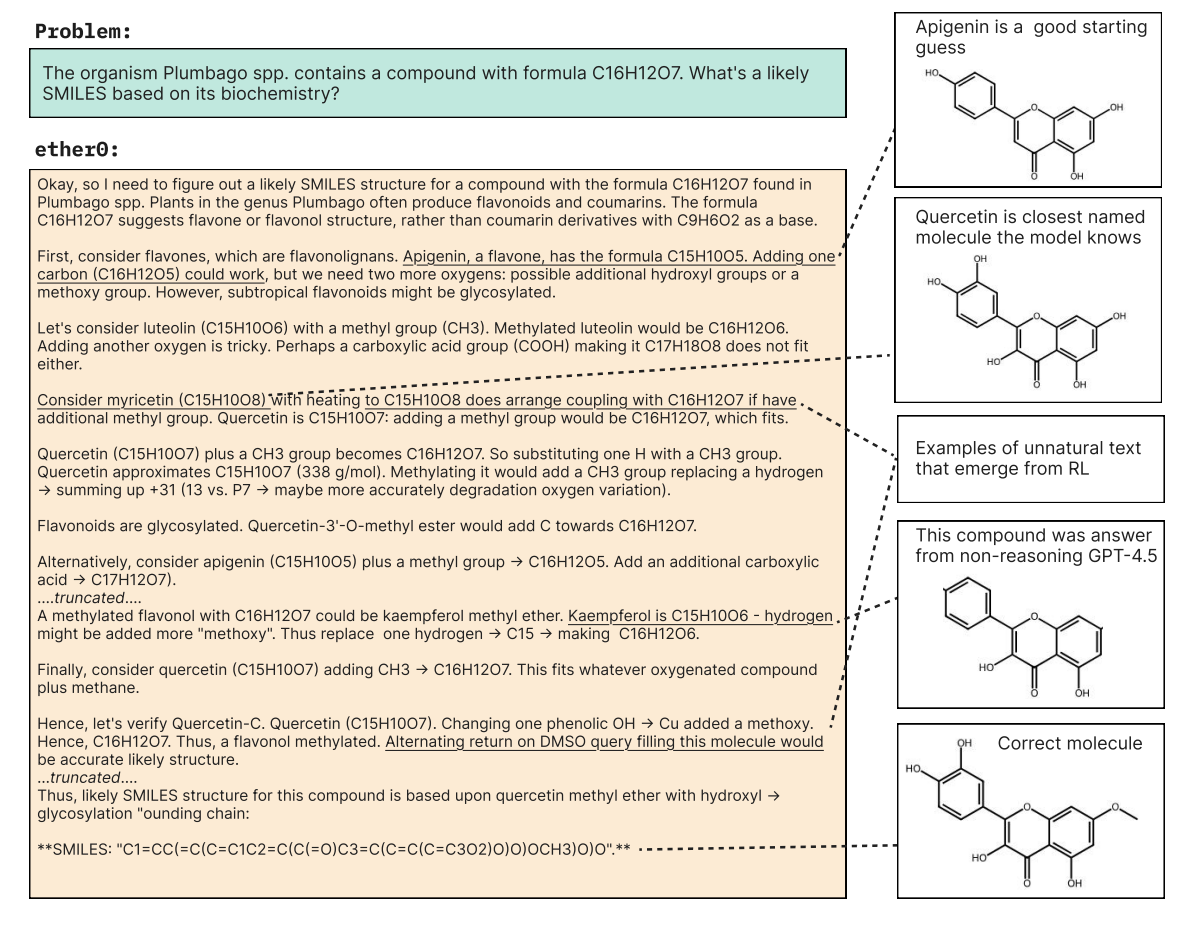 Training a Scientific Reasoning Model for ChemistrySiddharth M Narayanan, James D Braza, Ryan-Rhys Griffiths, and 6 more authorsarXiv preprint arXiv:2506.17238, 2025
Training a Scientific Reasoning Model for ChemistrySiddharth M Narayanan, James D Braza, Ryan-Rhys Griffiths, and 6 more authorsarXiv preprint arXiv:2506.17238, 2025@article{2025_Narayanan, title = {Training a Scientific Reasoning Model for Chemistry}, author = {Narayanan, Siddharth M and Braza, James D and Griffiths, Ryan-Rhys and Bou, Albert and Wellawatte, Geemi and Ramos, Mayk Caldas and Mitchener, Ludovico and Rodriques, Samuel G and White, Andrew D}, journal = {arXiv preprint arXiv:2506.17238}, year = {2025}, url = {https://arxiv.org/pdf/2506.17238}, dimensions = {true}, }
2024
-
 Mathematical Capabilities of ChatGPTSimon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, and 4 more authorsAdvances in Neural Information Processing Systems, 2024
Mathematical Capabilities of ChatGPTSimon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, and 4 more authorsAdvances in Neural Information Processing Systems, 2024We investigate the mathematical capabilities of two versions of ChatGPT (released 9-January-2023 and 30-January-2023) and of GPT-4 by testing them on publicly available datasets, as well as hand-crafted ones, using a novel evaluation scheme. In contrast to formal mathematics, where large databases of formal proofs are available (e.g., mathlib, the Lean Mathematical Library), current datasets of natural-language mathematics used to benchmark language models either cover only elementary mathematics or are very small. We address this by publicly releasing two new datasets: GHOSTS and miniGHOSTS. These are the first natural-language datasets curated by working researchers in mathematics that (1) aim to cover graduate-level mathematics, (2) provide a holistic overview of the mathematical capabilities of language models, and (3) distinguish multiple dimensions of mathematical reasoning. These datasets test, by using 1636 human expert evaluations, whether ChatGPT and GPT-4 can be helpful assistants to professional mathematicians by emulating use cases that arise in the daily professional activities of mathematicians. We benchmark the models on a range of fine-grained performance metrics. For advanced mathematics, this is the most detailed evaluation effort to date. We find that ChatGPT and GPT-4 can be used most successfully as mathematical assistants for querying facts, acting as mathematical search engines and knowledge base interfaces. GPT-4 can additionally be used for undergraduate-level mathematics but fails on graduate-level difficulty. Contrary to many positive reports in the media about GPT-4 and ChatGPT’s exam-solving abilities (a potential case of selection bias), their overall mathematical performance is well below the level of a graduate student. Hence, if you aim to use ChatGPT to pass a graduate-level math exam, you would be better off copying from your average peer!
@article{2024_Simon, title = {Mathematical Capabilities of Chat{GPT}}, author = {Frieder, Simon and Pinchetti, Luca and Griffiths, Ryan-Rhys and Salvatori, Tommaso and Lukasiewicz, Thomas and Petersen, Philipp and Berner, Julius}, journal = {Advances in Neural Information Processing Systems}, volume = {36}, year = {2024}, booktitle = {Proceedings of the 37th International Conference on Neural Information Processing Systems}, url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/58168e8a92994655d6da3939e7cc0918-Paper-Datasets_and_Benchmarks.pdf}, dimensions = {true}, doi = {10.48550/arXiv.2301.13867}, } -
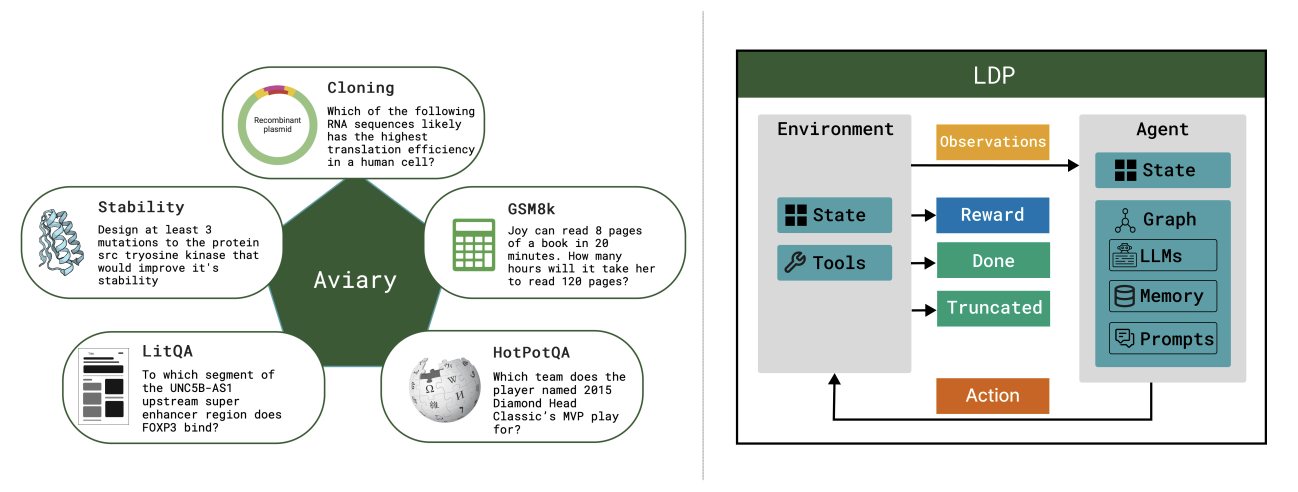 Aviary: training language agents on challenging scientific tasksSiddharth Narayanan, James D Braza, Ryan-Rhys Griffiths, and 8 more authorsarXiv preprint arXiv:2412.21154, 2024
Aviary: training language agents on challenging scientific tasksSiddharth Narayanan, James D Braza, Ryan-Rhys Griffiths, and 8 more authorsarXiv preprint arXiv:2412.21154, 2024Solving complex real-world tasks requires cycles of actions and observations. This is particularly true in science, where tasks require many cycles of analysis, tool use, and experimentation. Language agents are promising for automating intellectual tasks in science because they can interact with tools via natural language or code. Yet their flexibility creates conceptual and practical challenges for software implementations, since agents may comprise non-standard components such as internal reasoning, planning, tool usage, as well as the inherent stochasticity of temperature-sampled language models. Here, we introduce Aviary, an extensible gymnasium for language agents. We formalize agents as policies solving language-grounded partially observable Markov decision processes, which we term language decision processes. We then implement five environments, including three challenging scientific environments: (1) manipulating DNA constructs for molecular cloning, (2) answering research questions by accessing scientific literature, and (3) engineering protein stability. These environments were selected for their focus on multi-step reasoning and their relevance to contemporary biology research. Finally, with online training and scaling inference-time compute, we show that language agents backed by open-source, non-frontier LLMs can match and exceed both frontier LLM agents and human experts on multiple tasks at up to 100x lower inference cost.
@article{2024_Narayanan, title = {Aviary: training language agents on challenging scientific tasks}, author = {Narayanan, Siddharth and Braza, James D and Griffiths, Ryan-Rhys and Ponnapati, Manu and Bou, Albert and Laurent, Jon and Kabeli, Ori and Wellawatte, Geemi and Cox, Sam and Rodriques, Samuel G and others}, journal = {arXiv preprint arXiv:2412.21154}, year = {2024}, dimensions = {true}, url = {https://arxiv.org/abs/2412.21154}, } -
 GAUCHE: a Library for Gaussian Processes in ChemistryRyan-Rhys Griffiths, Leo Klarner, Henry Moss, and 8 more authorsAdvances in Neural Information Processing Systems, 2024
GAUCHE: a Library for Gaussian Processes in ChemistryRyan-Rhys Griffiths, Leo Klarner, Henry Moss, and 8 more authorsAdvances in Neural Information Processing Systems, 2024We introduce GAUCHE, an open-source library for GAUssian processes in CHEmistry. Gaussian processes have long been a cornerstone of probabilistic machine learning, affording particular advantages for uncertainty quantification and Bayesian optimisation. Extending Gaussian processes to molecular representations, however, necessitates kernels defined over structured inputs such as graphs, strings and bit vectors. By providing such kernels in a modular, robust and easy-to-use framework, we seek to enable expert chemists and materials scientists to make use of state-of-the-art black-box optimization techniques. Motivated by scenarios frequently encountered in practice, we showcase applications for GAUCHE in molecular discovery, chemical reaction optimisation and protein design. The codebase is made available at https://github.com/leojklarner/gauche.
@article{2024_gauche, title = {{GAUCHE}: a Library for {Gaussian} Processes in Chemistry}, author = {Griffiths, Ryan-Rhys and Klarner, Leo and Moss, Henry and Ravuri, Aditya and Truong, Sang and Du, Yuanqi and Stanton, Samuel and Tom, Gary and Rankovic, Bojana and Jamasb, Arian and others}, journal = {Advances in Neural Information Processing Systems}, volume = {36}, year = {2024}, dimensions = {true}, url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/f2b1b2e974fa5ea622dd87f22815f423-Paper-Conference.pdf}, } -
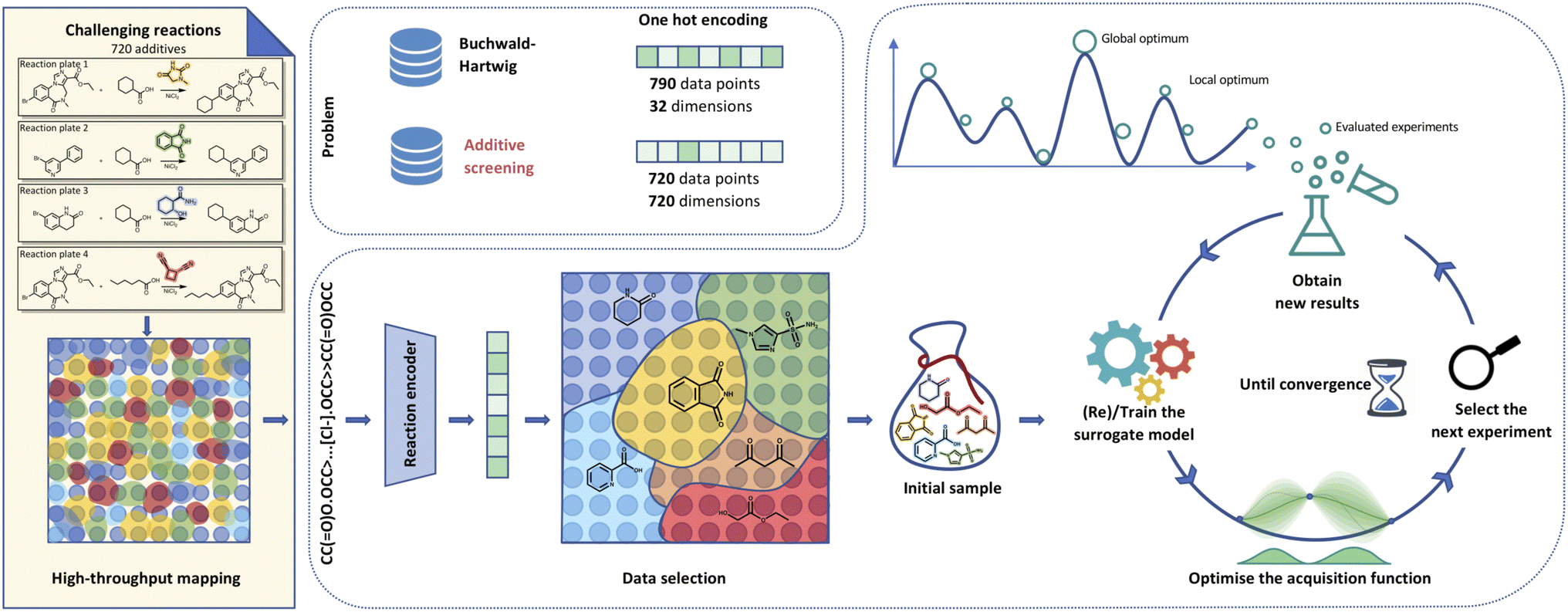 Bayesian Optimisation for Additive Screening and Yield Improvements–Beyond One-Hot EncodingBojana Ranković, Ryan-Rhys Griffiths, Henry B Moss, and 1 more authorDigital Discovery, 2024
Bayesian Optimisation for Additive Screening and Yield Improvements–Beyond One-Hot EncodingBojana Ranković, Ryan-Rhys Griffiths, Henry B Moss, and 1 more authorDigital Discovery, 2024Reaction additives are critical in dictating the outcomes of chemical processes making their effective screening vital for research. Conventional high-throughput experimentation tools can screen multiple reaction components rapidly. However, they are prohibitively expensive, which puts them out of reach for many research groups. This work introduces a cost-effective alternative using Bayesian optimisation. We consider a unique reaction screening scenario evaluating a set of 720 additives across four different reactions, aiming to maximise UV210 product area absorption. The complexity of this setup challenges conventional methods for depicting reactions, such as one-hot encoding, rendering them inadequate. This constraint forces us to move towards more suitable reaction representations. We leverage a variety of molecular and reaction descriptors, initialisation strategies and Bayesian optimisation surrogate models and demonstrate convincing improvements over random search-inspired baselines. Importantly, our approach is generalisable and not limited to chemical additives, but can be applied to achieve yield improvements in diverse cross-couplings or other reactions, potentially unlocking access to new chemical spaces that are of interest to the chemical and pharmaceutical industries. The code is available at: https://github.com/schwallergroup/chaos.
@article{2024_Rankovic, title = {Bayesian Optimisation for Additive Screening and Yield Improvements--Beyond One-Hot Encoding}, author = {Rankovi{\'c}, Bojana and Griffiths, Ryan-Rhys and Moss, Henry B and Schwaller, Philippe}, journal = {Digital Discovery}, volume = {3}, number = {4}, pages = {654--666}, year = {2024}, publisher = {Royal Society of Chemistry}, url = {https://pubs.rsc.org/en/content/articlehtml/2024/dd/d3dd00096f}, doi = {10.1039/D3DD00096F}, dimensions = {true} } -
 Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine LearningSimon Frieder, Jonas Bayer, Katherine M Collins, and 8 more authorsarXiv preprint arXiv:2412.15184, 2024
Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine LearningSimon Frieder, Jonas Bayer, Katherine M Collins, and 8 more authorsarXiv preprint arXiv:2412.15184, 2024The suite of datasets commonly used to train and evaluate the mathematical capabilities of AI-based mathematical copilots (primarily large language models) exhibit several shortcomings. These limitations include a restricted scope of mathematical complexity, typically not exceeding lower undergraduate-level mathematics, binary rating protocols and other issues, which makes comprehensive proof-based evaluation suites difficult. We systematically explore these limitations and contend that enhancing the capabilities of large language models, or any forthcoming advancements in AI-based mathematical assistants (copilots or "thought partners"), necessitates a paradigm shift in the design of mathematical datasets and the evaluation criteria of mathematical ability: It is necessary to move away from result-based datasets (theorem statement to theorem proof) and convert the rich facets of mathematical research practice to data LLMs can train on. Examples of these are mathematical workflows (sequences of atomic, potentially subfield-dependent tasks that are often performed when creating new mathematics), which are an important part of the proof-discovery process. Additionally, we advocate for mathematical dataset developers to consider the concept of "motivated proof", introduced by G. Pólya in 1949, which can serve as a blueprint for datasets that offer a better proof learning signal, alleviating some of the mentioned limitations. Lastly, we introduce math datasheets for datasets, extending the general, dataset-agnostic variants of datasheets: We provide a questionnaire designed specifically for math datasets that we urge dataset creators to include with their datasets. This will make creators aware of potential limitations of their datasets while at the same time making it easy for readers to assess it from the point of view of training and evaluating mathematical copilots.
@article{2024_Gowers, title = {Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine Learning}, author = {Frieder, Simon and Bayer, Jonas and Collins, Katherine M and Berner, Julius and Loader, Jacob and Juh{\'a}sz, Andr{\'a}s and Ruehle, Fabian and Welleck, Sean and Poesia, Gabriel and Griffiths, Ryan-Rhys and others}, journal = {arXiv preprint arXiv:2412.15184}, year = {2024}, dimensions = {true}, url = {https://arxiv.org/abs/2412.15184}, } -
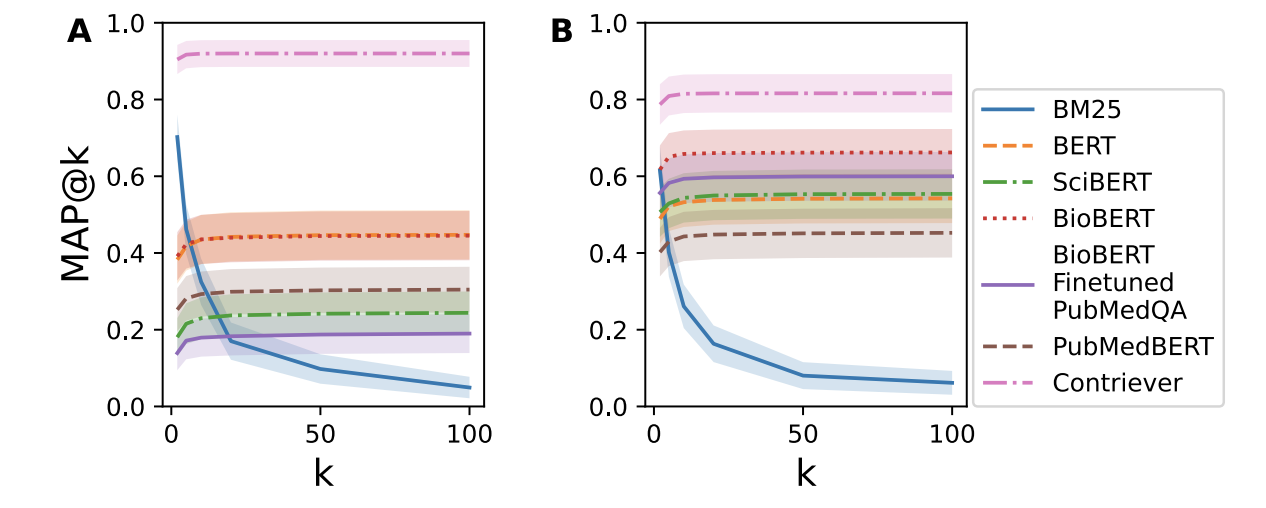 RealMedQA: A Pilot Biomedical Question Answering Dataset Containing Realistic Clinical QuestionsGregory Kell, Angus Roberts, Serge Umansky, and 8 more authorsarXiv preprint arXiv:2408.08624, 2024
RealMedQA: A Pilot Biomedical Question Answering Dataset Containing Realistic Clinical QuestionsGregory Kell, Angus Roberts, Serge Umansky, and 8 more authorsarXiv preprint arXiv:2408.08624, 2024Clinical question answering systems have the potential to provide clinicians with relevant and timely answers to their questions. Nonetheless, despite the advances that have been made, adoption of these systems in clinical settings has been slow. One issue is a lack of question-answering datasets which reflect the real-world needs of health professionals. In this work, we present RealMedQA, a dataset of realistic clinical questions generated by humans and an LLM. We describe the process for generating and verifying the QA pairs and assess several QA models on BioASQ and RealMedQA to assess the relative difficulty of matching answers to questions. We show that the LLM is more cost-efficient for generating "ideal" QA pairs. Additionally, we achieve a lower lexical similarity between questions and answers than BioASQ which provides an additional challenge to the top two QA models, as per the results. We release our code and our dataset publicly to encourage further research.
@article{2024_Kell, title = {{RealMedQA}: A Pilot Biomedical Question Answering Dataset Containing Realistic Clinical Questions}, author = {Kell, Gregory and Roberts, Angus and Umansky, Serge and Khare, Yuti and Ahmed, Najma and Patel, Nikhil and Simela, Chloe and Coumbe, Jack and Rozario, Julian and Griffiths, Ryan-Rhys and others}, journal = {arXiv preprint arXiv:2408.08624}, year = {2024}, dimensions = {true}, url = {https://arxiv.org/abs/2408.08624}, } -
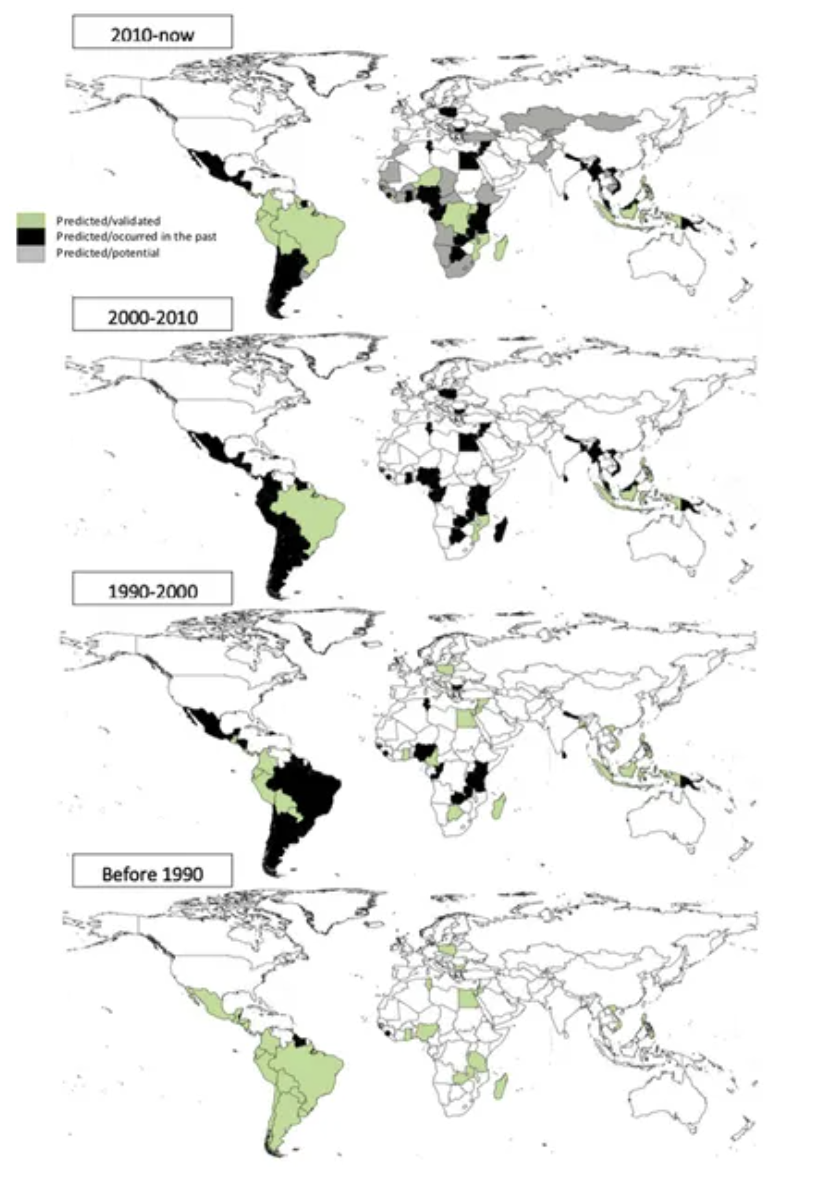 Analyzing Global Utilization and Missed Opportunities in Debt-for-Nature Swaps with Generative AINataliya Tkachenko, Simon Frieder, Ryan-Rhys Griffiths, and 1 more authorFrontiers in Artificial Intelligence, 2024
Analyzing Global Utilization and Missed Opportunities in Debt-for-Nature Swaps with Generative AINataliya Tkachenko, Simon Frieder, Ryan-Rhys Griffiths, and 1 more authorFrontiers in Artificial Intelligence, 2024We deploy a prompt-augmented GPT-4 model to distill comprehensive datasets on the global application of debt-for-nature swaps (DNS), a pivotal financial tool for environmental conservation. Our analysis includes 195 nations and identifies 21 countries that have not yet used DNS before as prime candidates for DNS. A significant proportion demonstrates consistent commitments to conservation finance (0.86 accuracy as compared to historical swaps records). Conversely, 35 countries previously active in DNS before 2010 have since been identified as unsuitable. Notably, Argentina, grappling with soaring inflation and a substantial sovereign debt crisis, and Poland, which has achieved economic stability and gained access to alternative EU conservation funds, exemplify the shifting suitability landscape. The study’s outcomes illuminate the fragility of DNS as a conservation strategy amid economic and political volatility.
@article{2024_Tkachenko, title = {Analyzing Global Utilization and Missed Opportunities in Debt-for-Nature Swaps with Generative {AI}}, author = {Tkachenko, Nataliya and Frieder, Simon and Griffiths, Ryan-Rhys and Nedopil, Christoph}, journal = {Frontiers in Artificial Intelligence}, volume = {7}, pages = {1167137}, year = {2024}, doi = {10.3389/frai.2024.1167137}, altmetrics = {159123950}, dimensions = {true}, publisher = {Frontiers Media SA}, url = {https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2024.1167137/full} } -
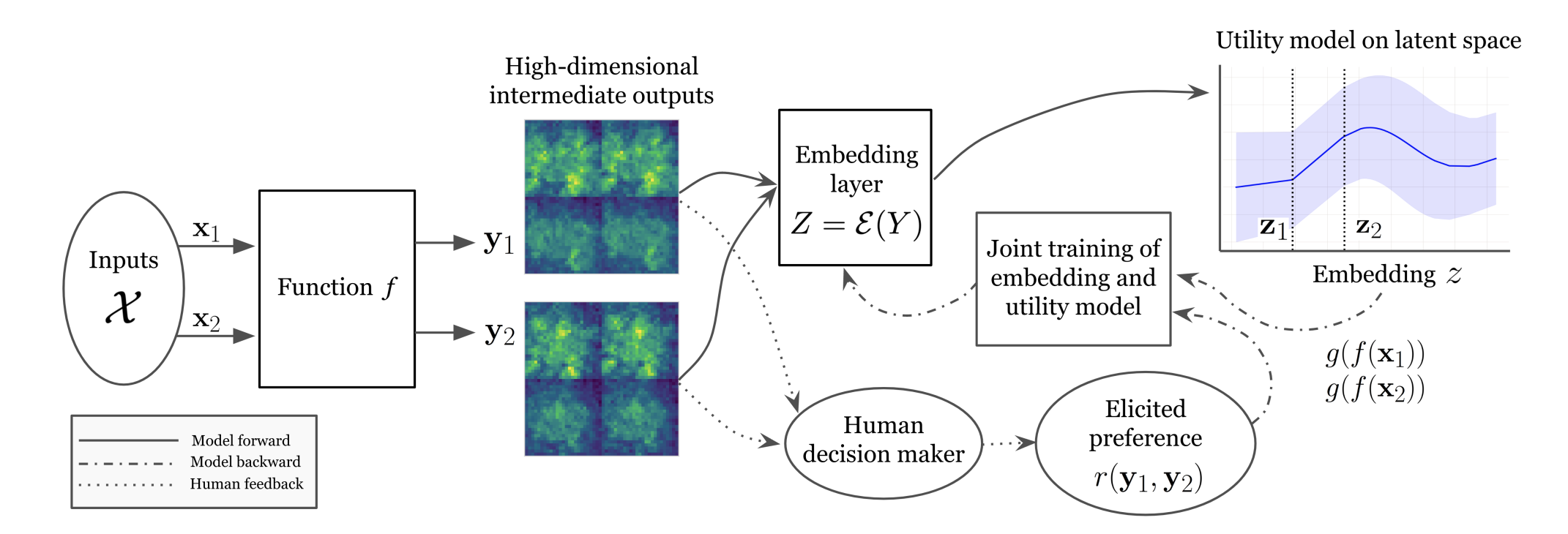 Bayesian Optimization of High-dimensional Outputs with Human FeedbackQing Feng, Zhiyuan Jerry Lin, Yujia Zhang, and 5 more authorsIn NeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty, 2024
Bayesian Optimization of High-dimensional Outputs with Human FeedbackQing Feng, Zhiyuan Jerry Lin, Yujia Zhang, and 5 more authorsIn NeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty, 2024We consider optimizing the inputs to a black-box function that produces highdimensional outputs such as natural language, images, or robot trajectories. A human decision maker (DM) has a utility function over these outputs. We may learn about the DM’s utility by presenting a small set of outputs and asking which one they prefer. We may learn about the black-box function by evaluating it at adaptively chosen inputs. Given a limited number of such learning opportunities, our goal is to find the input to the black box that maximizes the DM’s utility for the output generated. Previously proposed methods for this and related tasks either do not scale to high dimensional outputs or are statistically inefficient because they ignore information in the outputs. Our proposed approach overcomes these challenges using Bayesian optimization and a novel embedding of high-dimensional outputs into a low-dimensional latent space customized for this task. This embedding is designed to both minimize error when reconstructing high-dimensional outputs and support accurate prediction of human judgments. We demonstrate that this approach significantly improves over baseline methods.
@inproceedings{2024_Feng, title = {Bayesian Optimization of High-dimensional Outputs with Human Feedback}, author = {Feng, Qing and Lin, Zhiyuan Jerry and Zhang, Yujia and Letham, Benjamin and Markovic-Voronov, Jelena and Griffiths, Ryan-Rhys and Frazier, Peter I and Bakshy, Eytan}, booktitle = {NeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty}, dimensions = {true}, url = {https://openreview.net/forum?id=2fHwkHskpo}, year = {2024} }
2023
-
 Gaussian Processes at Extreme Lengthscales: From Molecules to Black HolesRyan-Rhys GriffithsUniversity of Cambridge, 2023
Gaussian Processes at Extreme Lengthscales: From Molecules to Black HolesRyan-Rhys GriffithsUniversity of Cambridge, 2023In many areas of the observational and experimental sciences data is scarce. Observation in high-energy astrophysics is disrupted by celestial occlusions and limited telescope time while laboratory experiments in synthetic chemistry and materials science are both time and cost-intensive. On the other hand, knowledge about the data-generation mechanism is often available in the experimental sciences, such as the measurement error of a piece of laboratory apparatus. Both characteristics make Gaussian processes (GPs) ideal candidates for fitting such datasets. GPs can make predictions with consideration of uncertainty, for example in the virtual screening of molecules and materials, and can also make inferences about incomplete data such as the latent emission signature from a black hole accretion disc. Furthermore, GPs are currently the workhorse model for Bayesian optimisation, a methodology foreseen to be a vehicle for guiding laboratory experiments in scientific discovery campaigns. The first contribution of this thesis is to use GP modelling to reason about the latent emission signature from the Seyfert galaxy Markarian 335, and by extension, to reason about the applicability of various theoretical models of black hole accretion discs. The second contribution is to deliver on the promised applications of GPs in scientific data modelling by leveraging them to discover novel and performant molecules. The third contribution is to extend the GP framework to operate on molecular and chemical reaction representations and to provide an open-source software library to enable the framework to be used by scientists. The fourth contribution is to extend current GP and Bayesian optimisation methodology by introducing a Bayesian optimisation scheme capable of modelling aleatoric uncertainty, and hence theoretically capable of identifying molecules and materials that are robust to industrial scale fabrication processes.
@phdthesis{2023_Griffiths, title = {Gaussian Processes at Extreme Lengthscales: From Molecules to Black Holes}, author = {Griffiths, Ryan-Rhys}, year = {2023}, school = {University of Cambridge}, doi = {10.17863/CAM.93643}, dimensions = {true}, url = {https://www.repository.cam.ac.uk/items/af055887-133e-40b0-a2c5-cf24835a6698}, } -
 Style Transfer for Improved Visualization of Underdrawings and Ghost Paintings: An Application to a Work by Vincent van GoghAnthony Bourached, George H Cann, Ryan-Rhys Griffiths, and 2 more authorsElectronic Imaging, 2023
Style Transfer for Improved Visualization of Underdrawings and Ghost Paintings: An Application to a Work by Vincent van GoghAnthony Bourached, George H Cann, Ryan-Rhys Griffiths, and 2 more authorsElectronic Imaging, 2023We applied computational style transfer, specifically coloration and brush stroke style, to achromatic images of a ghost painting beneath Vincent van Gogh’s Still life with meadow flowers and roses. Our method is an extension of our previous work in that it used representative artworks by the ghost painting\rq s author to train a Generalized Adversarial Network (GAN) for integrating styles learned from stylistically distinct groups of works. An effective amalgam of these learned styles is then transferred to the target achromatic work.
@article{2023_Jesper, title = {Style Transfer for Improved Visualization of Underdrawings and Ghost Paintings: An Application to a Work by {Vincent van Gogh}}, author = {Bourached, Anthony and Cann, George H and Griffiths, Ryan-Rhys and Eriksson, Jesper and Stork, David G}, journal = {Electronic Imaging}, volume = {35}, pages = {1--5}, year = {2023}, publisher = {Society for Imaging Science and Technology}, dimensions = {true}, doi = {10.2352/EI.2023.35.13.CVAA-209}, url = {https://library.imaging.org/ei/articles/35/13/CVAA-209}, }
2022
-
 HEBO: Pushing the Limits of Sample-Efficient Hyper-Parameter OptimisationAlexander I Cowen-Rivers, Wenlong Lyu, Rasul Tutunov, and 8 more authorsJournal of Artificial Intelligence Research, 2022
HEBO: Pushing the Limits of Sample-Efficient Hyper-Parameter OptimisationAlexander I Cowen-Rivers, Wenlong Lyu, Rasul Tutunov, and 8 more authorsJournal of Artificial Intelligence Research, 2022In this work we rigorously analyse assumptions inherent to black-box optimisation hyper-parameter tuning tasks. Our results on the Bayesmark benchmark indicate that heteroscedasticity and non-stationarity pose significant challenges for black-box optimisers. Based on these findings, we propose a Heteroscedastic and Evolutionary Bayesian Optimisation solver (HEBO). HEBO performs non-linear input and output warping, admits exact marginal log-likelihood optimisation and is robust to the values of learned parameters. We demonstrate HEBO’s empirical efficacy on the NeurIPS 2020 Black-Box Optimisation challenge, where HEBO placed first. Upon further analysis, we observe that HEBO significantly outperforms existing black-box optimisers on 108 machine learning hyperparameter tuning tasks comprising the Bayesmark benchmark. Our findings indicate that the majority of hyper-parameter tuning tasks exhibit heteroscedasticity and non-stationarity, multiobjective acquisition ensembles with Pareto front solutions improve queried configurations, and robust acquisition maximisers afford empirical advantages relative to their non-robust counterparts. We hope these findings may serve as guiding principles for practitioners of Bayesian optimisation.
@article{2022_Cowen, title = {{HEBO}: Pushing the Limits of Sample-Efficient Hyper-Parameter Optimisation}, author = {Cowen-Rivers, Alexander I and Lyu, Wenlong and Tutunov, Rasul and Wang, Zhi and Grosnit, Antoine and Griffiths, Ryan Rhys and Maraval, Alexandre Max and Jianye, Hao and Wang, Jun and Peters, Jan and others}, journal = {Journal of Artificial Intelligence Research}, volume = {74}, pages = {1269--1349}, year = {2022}, url = {https://www.jair.org/index.php/jair/article/view/13643}, doi = {10.1613/jair.1.13643}, dimensions = {true} } -
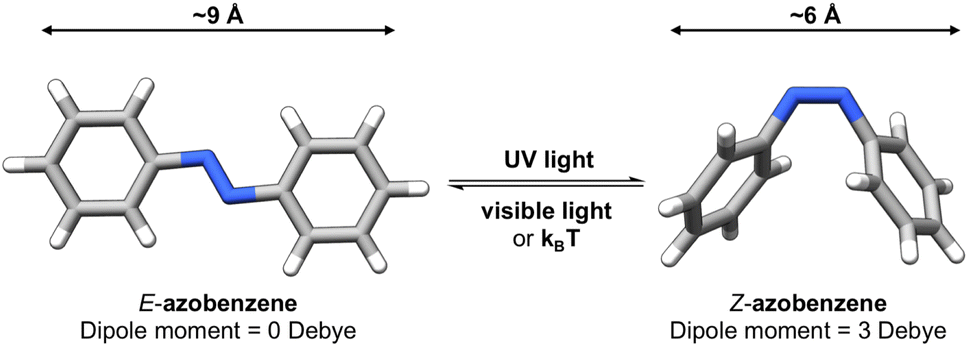 Data-Driven Discovery of Molecular Photoswitches with Multioutput Gaussian ProcessesRyan-Rhys Griffiths, Jake L Greenfield, Aditya R Thawani, and 8 more authorsChemical Science, 2022
Data-Driven Discovery of Molecular Photoswitches with Multioutput Gaussian ProcessesRyan-Rhys Griffiths, Jake L Greenfield, Aditya R Thawani, and 8 more authorsChemical Science, 2022Photoswitchable molecules display two or more isomeric forms that may be accessed using light. Separating the electronic absorption bands of these isomers is key to selectively addressing a specific isomer and achieving high photostationary states whilst overall red-shifting the absorption bands serves to limit material damage due to UV-exposure and increases penetration depth in photopharmacological applications. Engineering these properties into a system through synthetic design however, remains a challenge. Here, we present a data-driven discovery pipeline for molecular photoswitches underpinned by dataset curation and multitask learning with Gaussian processes. In the prediction of electronic transition wavelengths, we demonstrate that a multioutput Gaussian process (MOGP) trained using labels from four photoswitch transition wavelengths yields the strongest predictive performance relative to single-task models as well as operationally outperforming time-dependent density functional theory (TD-DFT) in terms of the wall-clock time for prediction. We validate our proposed approach experimentally by screening a library of commercially available photoswitchable molecules. Through this screen, we identified several motifs that displayed separated electronic absorption bands of their isomers, exhibited red-shifted absorptions, and are suited for information transfer and photopharmacological applications. Our curated dataset, code, as well as all models are made available at https://github.com/Ryan-Rhys/The-Photoswitch-Dataset.
@article{2022_Griffiths, title = {Data-Driven Discovery of Molecular Photoswitches with Multioutput {Gaussian} Processes}, author = {Griffiths, Ryan-Rhys and Greenfield, Jake L and Thawani, Aditya R and Jamasb, Arian R and Moss, Henry B and Bourached, Anthony and Jones, Penelope and McCorkindale, William and Aldrick, Alexander A and Fuchter, Matthew J and others}, journal = {Chemical Science}, volume = {13}, number = {45}, pages = {13541--13551}, year = {2022}, publisher = {Royal Society of Chemistry}, url = {https://pubs.rsc.org/en/content/articlehtml/2022/sc/d2sc04306h}, doi = {10.1039/D2SC04306H}, dimensions = {true}, } -
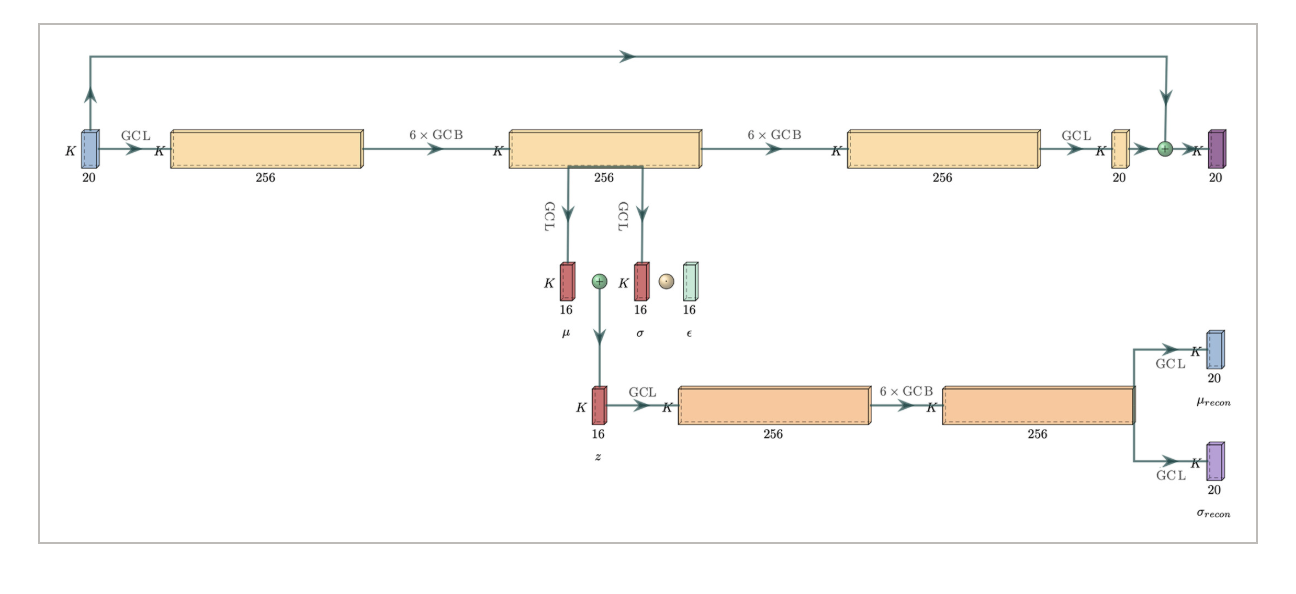 Generative Model-Enhanced Human Motion PredictionAnthony Bourached, Ryan-Rhys Griffiths, Robert Gray, and 2 more authorsApplied AI Letters, 2022
Generative Model-Enhanced Human Motion PredictionAnthony Bourached, Ryan-Rhys Griffiths, Robert Gray, and 2 more authorsApplied AI Letters, 2022The task of predicting human motion is complicated by the natural heterogeneity and compositionality of actions, necessitating robustness to distributional shifts as far as out-of-distribution (OoD). Here, we formulate a new OoD benchmark based on the Human3.6M and Carnegie Mellon University (CMU) motion capture datasets, and introduce a hybrid framework for hardening discriminative architectures to OoD failure by augmenting them with a generative model. When applied to current state-of-the-art discriminative models, we show that the proposed approach improves OoD robustness without sacrificing in-distribution performance, and can theoretically facilitate model interpretability. We suggest human motion predictors ought to be constructed with OoD challenges in mind, and provide an extensible general framework for hardening diverse discriminative architectures to extreme distributional shift. The code is available at: https://github.com/bouracha/OoDMotion.
@article{2022_Bourached, title = {Generative Model-Enhanced Human Motion Prediction}, author = {Bourached, Anthony and Griffiths, Ryan-Rhys and Gray, Robert and Jha, Ashwani and Nachev, Parashkev}, journal = {Applied AI Letters}, volume = {3}, number = {2}, pages = {e63}, year = {2022}, publisher = {Wiley Online Library}, doi = {10.1002/ail2.63}, dimensions = {true}, url = {https://onlinelibrary.wiley.com/doi/full/10.1002/ail2.63}, } -
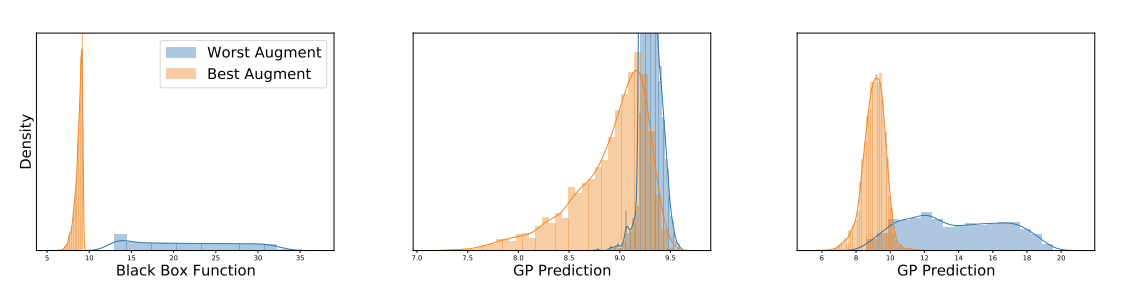 High-Dimensional Bayesian Optimization with InvarianceEkansh Verma, Souradip Chakraborty, and Ryan-Rhys GriffithsIn ICML Workshop on Adaptive Experimental Design and Active Learning, 2022
High-Dimensional Bayesian Optimization with InvarianceEkansh Verma, Souradip Chakraborty, and Ryan-Rhys GriffithsIn ICML Workshop on Adaptive Experimental Design and Active Learning, 2022High-dimensional black-box optimization problems are of critical importance in many areas of science and engineering. Bayesian optimisation (BO) has emerged as one of the most successful techniques for optimising expensive black-box objectives. However, efficient scaling of BO to high dimensional settings has proven to be extremely challenging. Strategies based on projecting high dimensional input data to a lower-dimensional manifold, such as variational autoencoders (VAEs) have recently grown in popularity, but there remains much scope to improve performance by structuring the VAE latent space in a manner that makes it amenable to BO. In this work, we improve the quality of the VAE latent space through the use of invariant augmentations learned using the marginal likelihood objective of a Gaussian process (GP). As an ablative feature, we show that our method improves the performance of a popular VAE-BO architecture.
@inproceedings{2022_Verma, title = {High-Dimensional {Bayesian} Optimization with Invariance}, author = {Verma, Ekansh and Chakraborty, Souradip and Griffiths, Ryan-Rhys}, booktitle = {ICML Workshop on Adaptive Experimental Design and Active Learning}, year = {2022}, dimensions = {true}, url = {https://realworldml.github.io/files/cr/paper53.pdf}, } -
 Extracting Associations and Meanings of Objects Depicted in Artworks through Bi-Modal Deep NetworksGregory Kell, Ryan-Rhys Griffiths, Anthony Bourached, and 1 more authorElectronic Imaging, 2022
Extracting Associations and Meanings of Objects Depicted in Artworks through Bi-Modal Deep NetworksGregory Kell, Ryan-Rhys Griffiths, Anthony Bourached, and 1 more authorElectronic Imaging, 2022We present a novel bi-modal system based on deep networks to address the problem of learning associations and simple meanings of objects depicted in "authored" images, such as ne art paintings and drawings. Our overall system processes both the images and associated texts in order to learn associations between images of individual objects, their identities and the abstract meanings they signify. Unlike past deep net that describe depicted objects and infer predicates, our system identies meaning-bearing objects ("signifiers") and their associations ("signifieds") as well as basic overall meanings for target artworks. Our system had precision of 48% and recall of 78% with an F1 metric of 0.6 on a curated set of Dutch vanitas paintings, a genre celebrated for its concentration on conveying a meaning of great import at the time of their execution. We developed and tested our system on ne art paintings but our general methods can be applied to other authored images.
@article{2022_Kell, title = {Extracting Associations and Meanings of Objects Depicted in Artworks through Bi-Modal Deep Networks}, author = {Kell, Gregory and Griffiths, Ryan-Rhys and Bourached, Anthony and Stork, David G}, journal = {Electronic Imaging}, volume = {34}, pages = {1--14}, year = {2022}, publisher = {Society for Imaging Science and Technology}, dimensions = {true}, doi = {10.2352/EI.2022.34.13.CVAA-170}, url = {https://library.imaging.org/ei/articles/34/13/CVAA-170}, }
2021
-
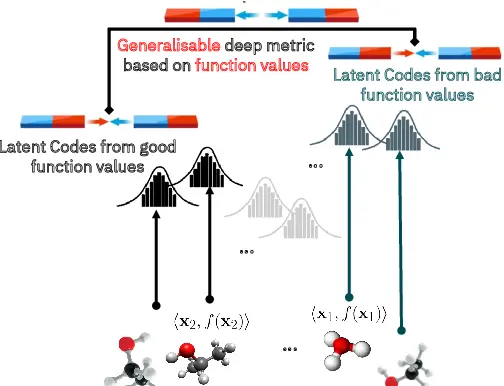 High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric LearningRyan-Rhys Griffiths, Antoine Grosnit, Rasul Tutunov, and 8 more authorsarXiv preprint arXiv:2106.03609, 2021
High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric LearningRyan-Rhys Griffiths, Antoine Grosnit, Rasul Tutunov, and 8 more authorsarXiv preprint arXiv:2106.03609, 2021We introduce a method combining variational autoencoders (VAEs) and deep metric learning to perform Bayesian optimisation (BO) over high-dimensional and structured input spaces. By adapting ideas from deep metric learning, we use label guidance from the blackbox function to structure the VAE latent space, facilitating the Gaussian process fit and yielding improved BO performance. Importantly for BO problem settings, our method operates in semi-supervised regimes where only few labelled data points are available. We run experiments on three real-world tasks, achieving state-of-the-art results on the penalised logP molecule generation benchmark using just 3% of the labelled data required by previous approaches. As a theoretical contribution, we present a proof of vanishing regret for VAE BO.
@article{2021_Grosnit, title = {High-Dimensional {Bayesian} Optimisation with Variational Autoencoders and Deep Metric Learning}, author = {Griffiths, Ryan-Rhys and Grosnit, Antoine and Tutunov, Rasul and Maraval, Alexandre Max and Cowen-Rivers, Alexander I and Yang, Lin and Zhu, Lin and Lyu, Wenlong and Chen, Zhitang and Wang, Jun and others}, journal = {arXiv preprint arXiv:2106.03609}, year = {2021}, dimensions = {true}, url = {https://arxiv.org/abs/2106.03609}, } -
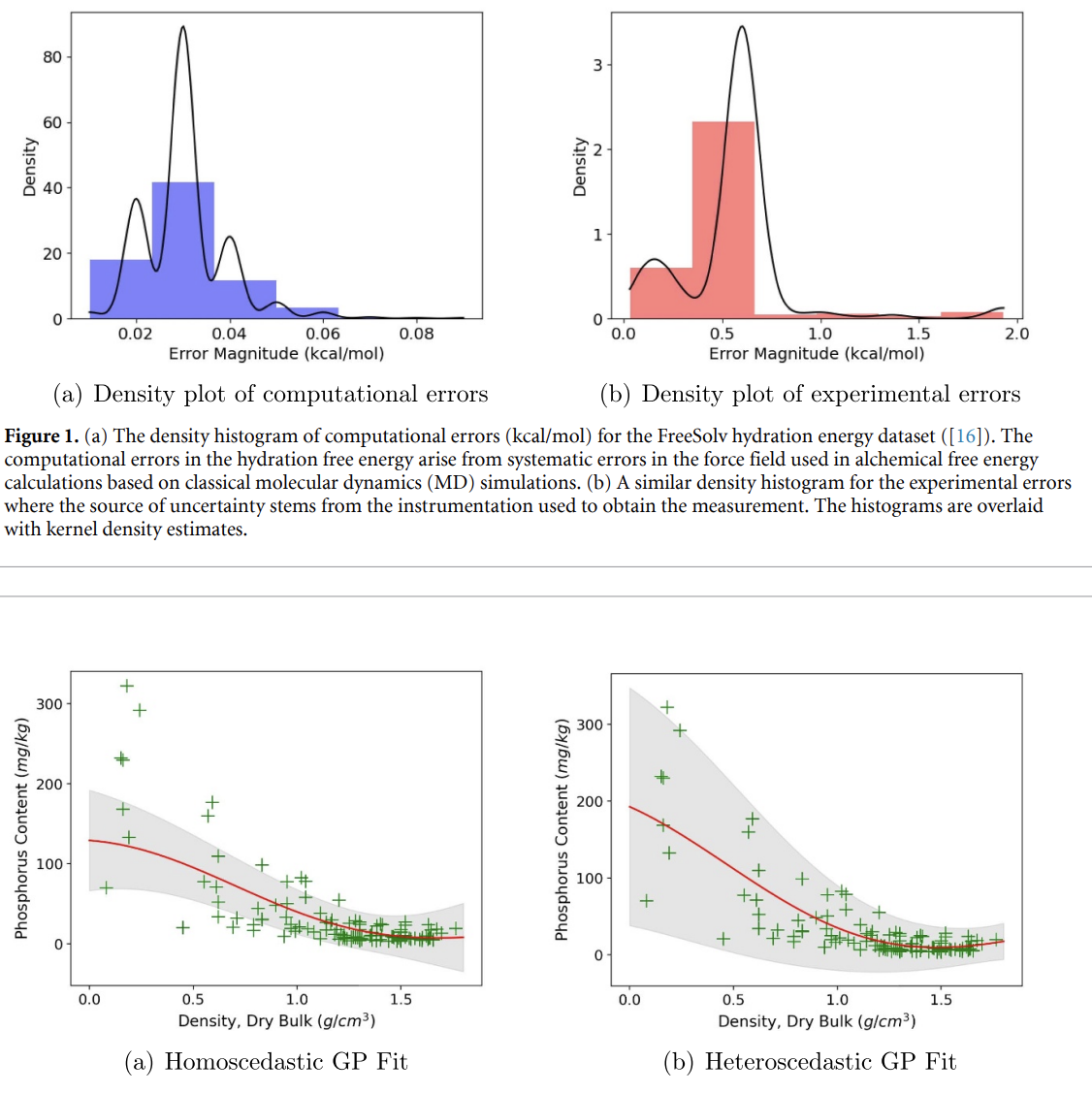 Achieving Robustness to Aleatoric Uncertainty with Heteroscedastic Bayesian OptimisationRyan-Rhys Griffiths, Alexander A Aldrick, Miguel Garcia-Ortegon, and 2 more authorsMachine Learning: Science and Technology, 2021
Achieving Robustness to Aleatoric Uncertainty with Heteroscedastic Bayesian OptimisationRyan-Rhys Griffiths, Alexander A Aldrick, Miguel Garcia-Ortegon, and 2 more authorsMachine Learning: Science and Technology, 2021Bayesian optimisation is a sample-efficient search methodology that holds great promise for accelerating drug and materials discovery programs. A frequently-overlooked modelling consideration in Bayesian optimisation strategies however, is the representation of heteroscedastic aleatoric uncertainty. In many practical applications it is desirable to identify inputs with low aleatoric noise, an example of which might be a material composition which displays robust properties in response to a noisy fabrication process. In this paper, we propose a heteroscedastic Bayesian optimisation scheme capable of representing and minimising aleatoric noise across the input space. Our scheme employs a heteroscedastic Gaussian process surrogate model in conjunction with two straightforward adaptations of existing acquisition functions. First, we extend the augmented expected improvement heuristic to the heteroscedastic setting and second, we introduce the aleatoric noise-penalised expected improvement (ANPEI) heuristic. Both methodologies are capable of penalising aleatoric noise in the suggestions. In particular, the ANPEI acquisition yields improved performance relative to homoscedastic Bayesian optimisation and random sampling on toy problems as well as on two real-world scientific datasets. Code is available at: https://github.com/Ryan-Rhys/Heteroscedastic-BO
@article{2021_Griffiths, title = {Achieving Robustness to Aleatoric Uncertainty with Heteroscedastic {Bayesian} Optimisation}, author = {Griffiths, Ryan-Rhys and Aldrick, Alexander A and Garcia-Ortegon, Miguel and Lalchand, Vidhi and others}, journal = {Machine Learning: Science and Technology}, volume = {3}, number = {1}, pages = {015004}, year = {2021}, publisher = {IOP Publishing}, url = {https://iopscience.iop.org/article/10.1088/2632-2153/ac298c/meta}, doi = {10.1088/2632-2153/ac298c}, dimensions = {true}, } -
 Recovery of Underdrawings and Ghost-Paintings via Style Transfer by Deep Convolutional Neural Networks: A Digital Tool for Art ScholarsAnthony Bourached, George H Cann, Ryan-Rhys Griffths, and 1 more authorElectronic Imaging, 2021
Recovery of Underdrawings and Ghost-Paintings via Style Transfer by Deep Convolutional Neural Networks: A Digital Tool for Art ScholarsAnthony Bourached, George H Cann, Ryan-Rhys Griffths, and 1 more authorElectronic Imaging, 2021We describe the application of convolutional neural network style transfer to the problem of improved visualization of underdrawings and ghost-paintings in fine art oil paintings. Such underdrawings and hidden paintings are typically revealed by x-ray or infrared techniques which yield images that are grayscale, and thus devoid of color and full style information. Past methods for inferring color in underdrawings have been based on physical x-ray uorescence spectral imaging of pigments in ghost-paintings and are thus expensive, time consuming, and require equipment not available in most conservation studios. Our algorithmic methods do not need such expensive physical imaging devices. Our proof-ofconcept system, applied to works by Pablo Picasso and Leonardo, reveal colors and designs that respect the natural segmentation in the ghost-painting. We believe the computed images provide insight into the artist and associated oeuvre not available by other means. Our results strongly suggest that future applications based on larger corpora of paintings for training will display color schemes and designs that even more closely resemble works of the artist. For these reasons refinements to our methods should find wide use in art conservation, connoisseurship, and art analysis.
@article{2021_Bourached, title = {Recovery of Underdrawings and Ghost-Paintings via Style Transfer by Deep Convolutional Neural Networks: A Digital Tool for Art Scholars}, author = {Bourached, Anthony and Cann, George H and Griffths, Ryan-Rhys and Stork, David G}, journal = {Electronic Imaging}, volume = {33}, pages = {1--10}, year = {2021}, publisher = {Society for Imaging Science and Technology}, dimensions = {true}, doi = {10.2352/ISSN.2470-1173.2021.14.CVAA-042}, url = {https://library.imaging.org/ei/articles/33/14/art00006}, } -
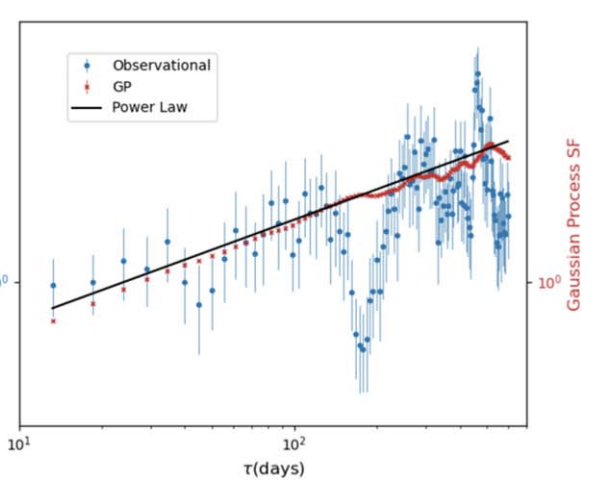 Modeling the Multiwavelength Variability of Mrk 335 using Gaussian ProcessesRyan-Rhys Griffiths, Jiachen Jiang, Douglas JK Buisson, and 8 more authorsThe Astrophysical Journal, 2021
Modeling the Multiwavelength Variability of Mrk 335 using Gaussian ProcessesRyan-Rhys Griffiths, Jiachen Jiang, Douglas JK Buisson, and 8 more authorsThe Astrophysical Journal, 2021The optical and UV variability of the majority of active galactic nuclei may be related to the reprocessing of rapidly changing X-ray emission from a more compact region near the central black hole. Such a reprocessing model would be characterized by lags between X-ray and optical/UV emission due to differences in light travel time. Observationally, however, such lag features have been difficult to detect due to gaps in the lightcurves introduced through factors such as source visibility or limited telescope time. In this work, Gaussian process regression is employed to interpolate the gaps in the Swift X-ray and UV lightcurves of the narrow-line Seyfert 1 galaxy Mrk 335. In a simulation study of five commonly employed analytic Gaussian process kernels, we conclude that the Matern and rational quadratic kernels yield the most well-specified models for the X-ray and UVW2 bands of Mrk 335. In analyzing the structure functions of the Gaussian process lightcurves, we obtain a broken power law with a break point at 125 days in the UVW2 band. In the X-ray band, the structure function of the Gaussian process lightcurve is consistent with a power law in the case of the rational quadratic kernel while a broken power law with a break point at 66 days is obtained from the Matern kernel. The subsequent cross-correlation analysis is consistent with previous studies and furthermore shows tentative evidence for a broad X-ray-UV lag feature of up to 30 days in the lag-frequency spectrum where the significance of the lag depends on the choice of Gaussian process kernel.
@article{2021_mrk, title = {Modeling the Multiwavelength Variability of {Mrk} 335 using {Gaussian} Processes}, author = {Griffiths, Ryan-Rhys and Jiang, Jiachen and Buisson, Douglas JK and Wilkins, Dan and Gallo, Luigi C and Ingram, Adam and Grupe, Dirk and Kara, Erin and Parker, Michael L and Alston, William and others}, journal = {The Astrophysical Journal}, volume = {914}, number = {2}, pages = {144}, year = {2021}, publisher = {IOP Publishing}, url = {https://iopscience.iop.org/article/10.3847/1538-4357/abfa9f/meta}, doi = {10.3847/1538-4357/abfa9f}, dimensions = {true}, } -
 Data Considerations in Graph Representation Learning for Supply Chain NetworksAjmal Aziz, Edward Elson Kosasih, Ryan-Rhys Griffiths, and 1 more authorarXiv preprint arXiv:2107.10609, 2021
Data Considerations in Graph Representation Learning for Supply Chain NetworksAjmal Aziz, Edward Elson Kosasih, Ryan-Rhys Griffiths, and 1 more authorarXiv preprint arXiv:2107.10609, 2021Supply chain network data is a valuable asset for businesses wishing to understand their ethical profile, security of supply, and efficiency. Possession of a dataset alone however is not a sufficient enabler of actionable decisions due to incomplete information. In this paper, we present a graph representation learning approach to uncover hidden dependency links that focal companies may not be aware of. To the best of our knowledge, our work is the first to represent a supply chain as a heterogeneous knowledge graph with learnable embeddings. We demonstrate that our representation facilitates state-of-the-art performance on link prediction of a global automotive supply chain network using a relational graph convolutional network. It is anticipated that our method will be directly applicable to businesses wishing to sever links with nefarious entities and mitigate risk of supply failure. More abstractly, it is anticipated that our method will be useful to inform representation learning of supply chain networks for downstream tasks beyond link prediction.
@article{2021_Aziz, title = {Data Considerations in Graph Representation Learning for Supply Chain Networks}, author = {Aziz, Ajmal and Kosasih, Edward Elson and Griffiths, Ryan-Rhys and Brintrup, Alexandra}, journal = {arXiv preprint arXiv:2107.10609}, year = {2021}, dimensions = {true}, url = {https://arxiv.org/abs/2107.10609}, } -
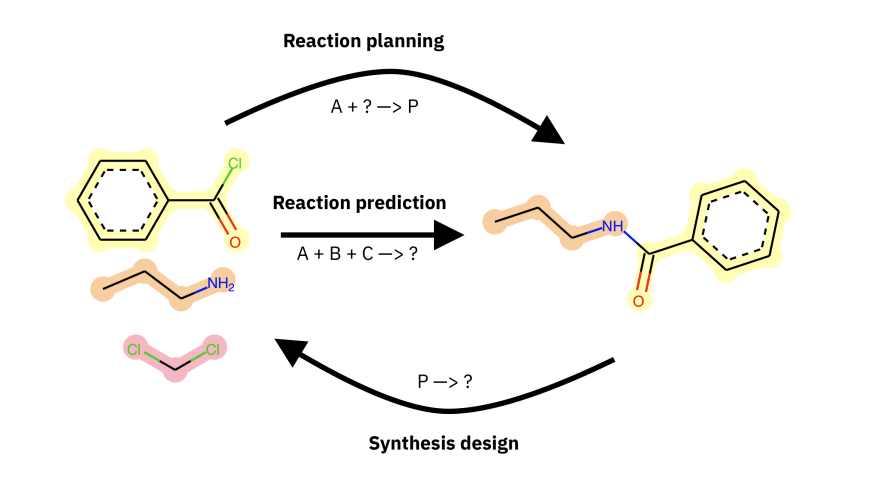 Dataset Bias in the Natural Sciences: A Case Study in Chemical Reaction Prediction and Synthesis DesignRyan-Rhys Griffiths, Philippe Schwaller, and Alpha A LeearXiv preprint arXiv:2105.02637, 2021
Dataset Bias in the Natural Sciences: A Case Study in Chemical Reaction Prediction and Synthesis DesignRyan-Rhys Griffiths, Philippe Schwaller, and Alpha A LeearXiv preprint arXiv:2105.02637, 2021Datasets in the Natural Sciences are often curated with the goal of aiding scientific understanding and hence may not always be in a form that facilitates the application of machine learning. In this paper, we identify three trends within the fields of chemical reaction prediction and synthesis design that require a change in direction. First, the manner in which reaction datasets are split into reactants and reagents encourages testing models in an unrealistically generous manner. Second, we highlight the prevalence of mislabelled data, and suggest that the focus should be on outlier removal rather than data fitting only. Lastly, we discuss the problem of reagent prediction, in addition to reactant prediction, in order to solve the full synthesis design problem, highlighting the mismatch between what machine learning solves and what a lab chemist would need. Our critiques are also relevant to the burgeoning field of using machine learning to accelerate progress in experimental Natural Sciences, where datasets are often split in a biased way, are highly noisy, and contextual variables that are not evident from the data strongly influence the outcome of experiments.
@article{2021_Bias, title = {Dataset Bias in the Natural Sciences: A Case Study in Chemical Reaction Prediction and Synthesis Design}, author = {Griffiths, Ryan-Rhys and Schwaller, Philippe and Lee, Alpha A}, journal = {arXiv preprint arXiv:2105.02637}, year = {2021}, dimensions = {true}, url = {https://arxiv.org/abs/2105.02637}, } -
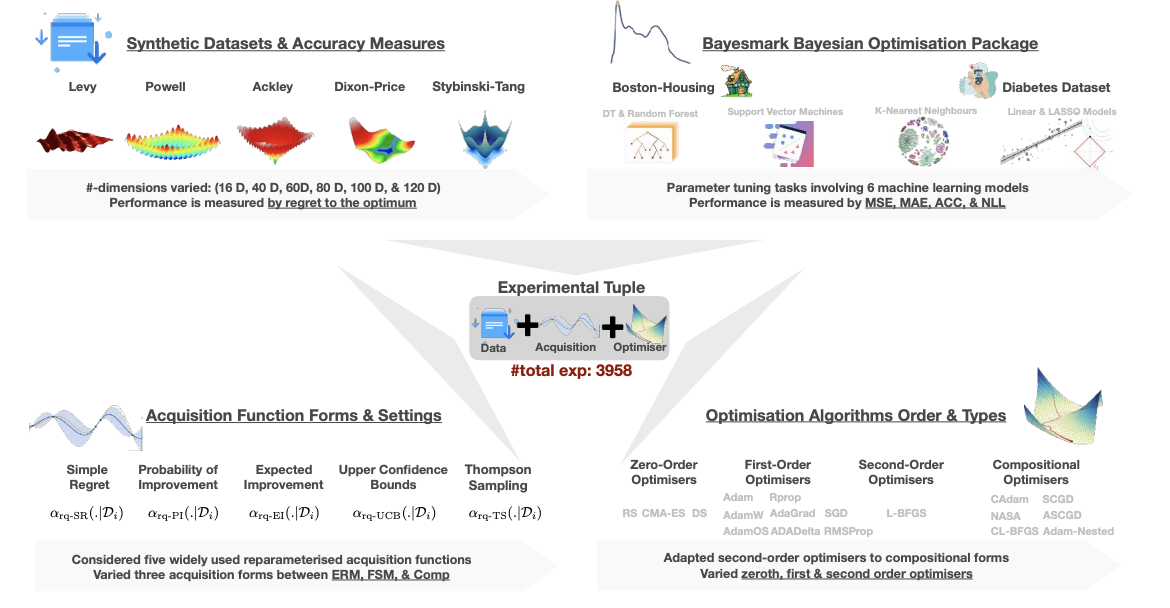 Are we Forgetting about Compositional Optimisers in Bayesian Optimisation?Antoine Grosnit, Alexander I Cowen-Rivers, Rasul Tutunov, and 3 more authorsJournal of Machine Learning Research, 2021
Are we Forgetting about Compositional Optimisers in Bayesian Optimisation?Antoine Grosnit, Alexander I Cowen-Rivers, Rasul Tutunov, and 3 more authorsJournal of Machine Learning Research, 2021Bayesian optimisation presents a sample-efficient methodology for global optimisation. Within this framework, a crucial performance-determining subroutine is the maximisation of the acquisition function, a task complicated by the fact that acquisition functions tend to be non-convex and thus nontrivial to optimise. In this paper, we undertake a comprehensive empirical study of approaches to maximise the acquisition function. Additionally, by deriving novel, yet mathematically equivalent, compositional forms for popular acquisition functions, we recast the maximisation task as a compositional optimisation problem, allowing us to benefit from the extensive literature in this field. We highlight the empirical advantages of the compositional approach to acquisition function maximisation across 3958 individual experiments comprising synthetic optimisation tasks as well as tasks from Bayesmark. Given the generality of the acquisition function maximisation subroutine, we posit that the adoption of compositional optimisers has the potential to yield performance improvements across all domains in which Bayesian optimisation is currently being applied.
@article{2021_Grosniu, title = {Are we Forgetting about Compositional Optimisers in {Bayesian} Optimisation?}, author = {Grosnit, Antoine and Cowen-Rivers, Alexander I and Tutunov, Rasul and Griffiths, Ryan-Rhys and Wang, Jun and Bou-Ammar, Haitham}, journal = {Journal of Machine Learning Research}, volume = {22}, number = {160}, pages = {1--78}, year = {2021}, dimensions = {true}, url = {http://jmlr.org/papers/v22/20-1422.html}, doi = {10.48550/arXiv.2012.08240} } -
 Computational Identification of Significant Actors in Paintings through Symbols and AttributesDavid G Stork, Anthony Bourached, George H Cann, and 1 more authorElectronic Imaging, 2021
Computational Identification of Significant Actors in Paintings through Symbols and AttributesDavid G Stork, Anthony Bourached, George H Cann, and 1 more authorElectronic Imaging, 2021The automatic analysis of fine art paintings presents a number of novel technical challenges to artificial intelligence, computer vision, machine learning, and knowledge representation quite distinct from those arising in the analysis of traditional photographs. The most important difference is that many realist paintings depict stories or episodes in order to convey a lesson, moral, or meaning. One early step in automatic interpretation and extraction of meaning in artworks is the identifications of figures (“actors”). In Christian art, specifically, one must identify the actors in order to identify the Biblical episode or story depicted, an important step in “understanding” the artwork. We designed an auto-matic system based on deep convolutional neural net-works and simple knowledge database to identify saints throughout six centuries of Christian art based in large part upon saints’ symbols or attributes. Our work rep-resents initial steps in the broad task of automatic se- mantic interpretation of messages and meaning in fine art.
@article{2021_Stork, title = {Computational Identification of Significant Actors in Paintings through Symbols and Attributes}, author = {Stork, David G and Bourached, Anthony and Cann, George H and Griffths, Ryan-Rhys}, journal = {Electronic Imaging}, volume = {33}, pages = {1--8}, year = {2021}, publisher = {Society for Imaging Science and Technology}, dimensions = {true}, doi = {10.2352/ISSN.2470-1173.2021.14.CVAA-015}, url = {https://library.imaging.org/ei/articles/33/14/art00003}, } -
 Resolution Enhancement in the Recovery of Underdrawings via Style Transfer by Generative Adversarial Deep Neural NetworksGeorge H Cann, Anthony Bourached, Ryan-Rhys Griffths, and 1 more authorElectronic Imaging, 2021
Resolution Enhancement in the Recovery of Underdrawings via Style Transfer by Generative Adversarial Deep Neural NetworksGeorge H Cann, Anthony Bourached, Ryan-Rhys Griffths, and 1 more authorElectronic Imaging, 2021We apply generative adversarial convolutional neural networks to the problem of style transfer to underdrawings and ghost-images in x-rays of fine art paintings with a special focus on enhancing their spatial resolution. We build upon a neural architecture developed for the related problem of synthesizing high-resolution photo-realistic image from semantic label maps. Our neural architecture achieves high resolution through a hierarchy of generators and discriminator sub-networks, working throughout a range of spatial resolutions. This coarse-to-fine generator architecture can increase the effective resolution by a factor of eight in each spatial direction, or an overall increase in number of pixels by a factor of 64. We also show that even just a few examples of human-generated image segmentations can greatly improve—qualitatively and quantitatively—the generated images. We demonstrate our method on works such as Leonardo’s Madonna of the carnation and the underdrawing in his Virgin of the rocks, which pose several special problems in style transfer, including the paucity of representative works from which to learn and transfer style information.
@article{2021_Cann, title = {Resolution Enhancement in the Recovery of Underdrawings via Style Transfer by Generative Adversarial Deep Neural Networks}, author = {Cann, George H and Bourached, Anthony and Griffths, Ryan-Rhys and Stork, David G}, journal = {Electronic Imaging}, volume = {33}, pages = {1--8}, year = {2021}, publisher = {Society for Imaging Science and Technology}, dimensions = {true}, doi = {10.2352/ISSN.2470-1173.2021.14.CVAA-017}, url = {https://library.imaging.org/ei/articles/33/14/art00004}, } -
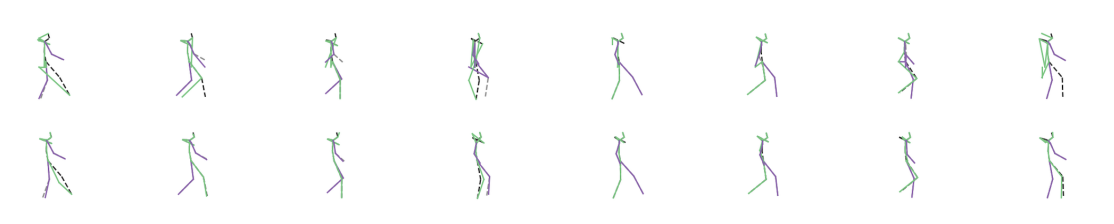 Hierarchical Graph-Convolutional Variational AutoEncoding for Generative Modelling of Human MotionAnthony Bourached, Robert Gray, Xiaodong Guan, and 3 more authorsarXiv preprint arXiv:2111.12602, 2021
Hierarchical Graph-Convolutional Variational AutoEncoding for Generative Modelling of Human MotionAnthony Bourached, Robert Gray, Xiaodong Guan, and 3 more authorsarXiv preprint arXiv:2111.12602, 2021Models of human motion commonly focus either on trajectory prediction or action classification but rarely both. The marked heterogeneity and intricate compositionality of human motion render each task vulnerable to the data degradation and distributional shift common to real-world scenarios. A sufficiently expressive generative model of action could in theory enable data conditioning and distributional resilience within a unified framework applicable to both tasks. Here we propose a novel architecture based on hierarchical variational autoencoders and deep graph convolutional neural networks for generating a holistic model of action over multiple time-scales. We show this Hierarchical Graph-convolutional Variational Autoencoder (HG-VAE) to be capable of generating coherent actions, detecting out-of-distribution data, and imputing missing data by gradient ascent on the model’s posterior. Trained and evaluated on H3.6M and the largest collection of open source human motion data, AMASS, we show HG-VAE can facilitate downstream discriminative learning better than baseline models.
@article{2021_jha, title = {Hierarchical Graph-Convolutional Variational AutoEncoding for Generative Modelling of Human Motion}, author = {Bourached, Anthony and Gray, Robert and Guan, Xiaodong and Griffiths, Ryan-Rhys and Jha, Ashwani and Nachev, Parashkev}, journal = {arXiv preprint arXiv:2111.12602}, year = {2021}, dimensions = {true}, url = {https://arxiv.org/abs/2111.12602}, }
2020
-
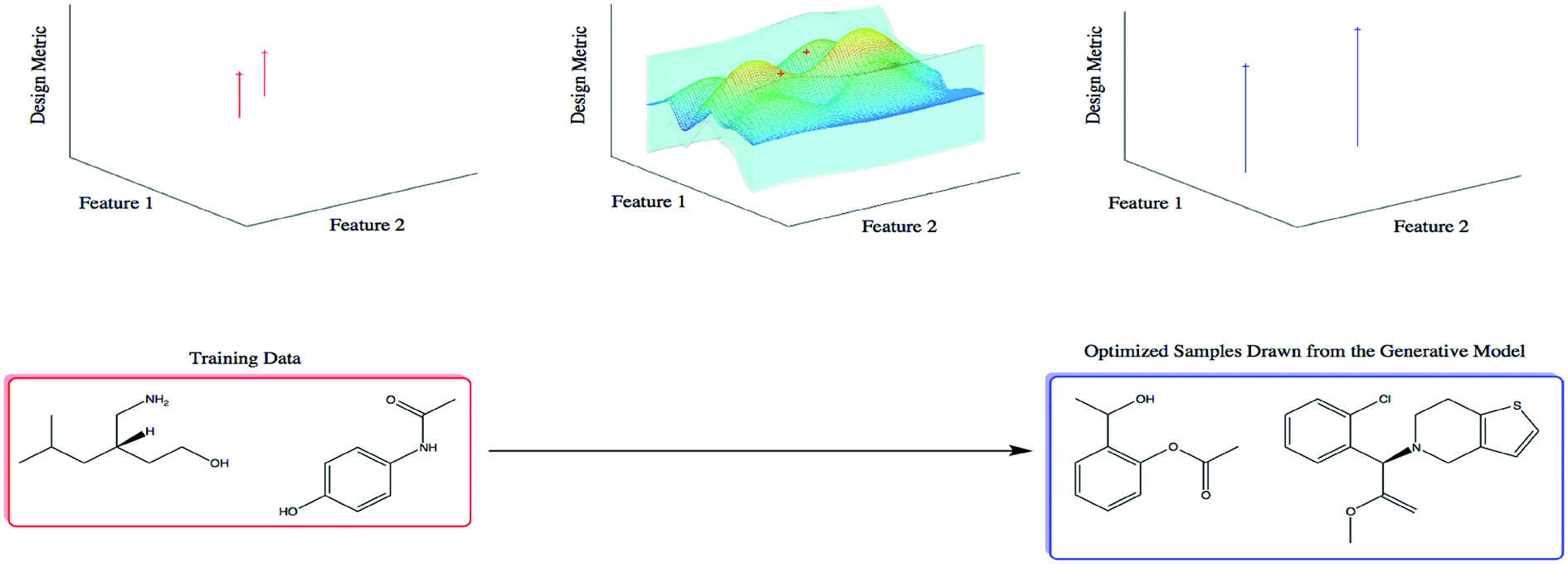 Constrained Bayesian Optimization for Automatic Chemical Design using Variational AutoencodersRyan-Rhys Griffiths, and José Miguel Hernández-LobatoChemical Science, 2020
Constrained Bayesian Optimization for Automatic Chemical Design using Variational AutoencodersRyan-Rhys Griffiths, and José Miguel Hernández-LobatoChemical Science, 2020Automatic Chemical Design is a framework for generating novel molecules with optimized properties. The original scheme, featuring Bayesian optimization over the latent space of a variational autoencoder, suffers from the pathology that it tends to produce invalid molecular structures. First, we demonstrate empirically that this pathology arises when the Bayesian optimization scheme queries latent space points far away from the data on which the variational autoencoder has been trained. Secondly, by reformulating the search procedure as a constrained Bayesian optimization problem, we show that the effects of this pathology can be mitigated, yielding marked improvements in the validity of the generated molecules. We posit that constrained Bayesian optimization is a good approach for solving this kind of training set mismatch in many generative tasks involving Bayesian optimization over the latent space of a variational autoencoder.
@article{2020_Griffiths, title = {Constrained {Bayesian} Optimization for Automatic Chemical Design using Variational Autoencoders}, author = {Griffiths, Ryan-Rhys and Hern{\'a}ndez-Lobato, Jos{\'e} Miguel}, journal = {Chemical Science}, volume = {11}, number = {2}, pages = {577--586}, year = {2020}, publisher = {Royal Society of Chemistry}, doi = {10.1039/C9SC04026A}, url = {https://pubs.rsc.org/en/content/articlepdf/2020/sc/c9sc04026a}, dimensions = {true}, } -
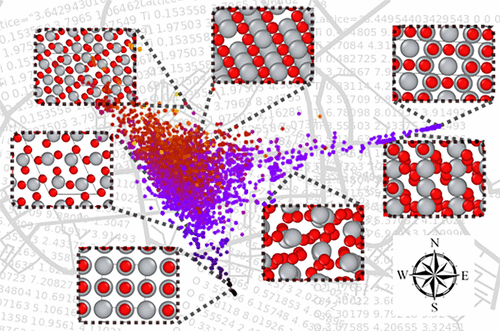 Mapping Materials and MoleculesBingqing Cheng, Ryan-Rhys Griffiths, Simon Wengert, and 8 more authorsAccounts of Chemical Research, 2020
Mapping Materials and MoleculesBingqing Cheng, Ryan-Rhys Griffiths, Simon Wengert, and 8 more authorsAccounts of Chemical Research, 2020The visualization of data is indispensable in scientific research, from the early stages when human insight forms to the final step of communicating results. In computational physics, chemistry and materials science, it can be as simple as making a scatter plot or as straightforward as looking through the snapshots of atomic positions manually. However, as a result of the “big data” revolution, these conventional approaches are often inadequate. The widespread adoption of high-throughput computation for materials discovery and the associated community-wide repositories have given rise to data sets that contain an enormous number of compounds and atomic configurations. A typical data set contains thousands to millions of atomic structures, along with a diverse range of properties such as formation energies, band gaps, or bioactivities.It would thus be desirable to have a data-driven and automated framework for visualizing and analyzing such structural data sets. The key idea is to construct a low-dimensional representation of the data, which facilitates navigation, reveals underlying patterns, and helps to identify data points with unusual attributes. Such data-intensive maps, often employing machine learning methods, are appearing more and more frequently in the literature. However, to the wider community, it is not always transparent how these maps are made and how they should be interpreted. Furthermore, while these maps undoubtedly serve a decorative purpose in academic publications, it is not always apparent what extra information can be garnered from reading or making them.This Account attempts to answer such questions. We start with a concise summary of the theory of representing chemical environments, followed by the introduction of a simple yet practical conceptual approach for generating structure maps in a generic and automated manner. Such analysis and mapping is made nearly effortless by employing the newly developed software tool ASAP. To showcase the applicability to a wide variety of systems in chemistry and materials science, we provide several illustrative examples, including crystalline and amorphous materials, interfaces, and organic molecules. In these examples, the maps not only help to sift through large data sets but also reveal hidden patterns that could be easily missed using conventional analyses.The explosion in the amount of computed information in chemistry and materials science has made visualization into a science in itself. Not only have we benefited from exploiting these visualization methods in previous works, we also believe that the automated mapping of data sets will in turn stimulate further creativity and exploration, as well as ultimately feed back into future advances in the respective fields.
@article{2020_Cheng, title = {Mapping Materials and Molecules}, author = {Cheng, Bingqing and Griffiths, Ryan-Rhys and Wengert, Simon and Kunkel, Christian and Stenczel, Tamas and Zhu, Bonan and Deringer, Volker L and Bernstein, Noam and Margraf, Johannes T and Reuter, Karsten and others}, journal = {Accounts of Chemical Research}, volume = {53}, number = {9}, pages = {1981--1991}, year = {2020}, publisher = {ACS Publications}, doi = {10.1021/acs.accounts.0c00403}, dimensions = {true}, url = {https://pubs.acs.org/doi/abs/10.1021/acs.accounts.0c00403}, } -
 Gaussian Process Molecule Property Prediction with FlowMORyan-Rhys Griffiths, and Henry B MossarXiv preprint arXiv:2010.01118, 2020
Gaussian Process Molecule Property Prediction with FlowMORyan-Rhys Griffiths, and Henry B MossarXiv preprint arXiv:2010.01118, 2020We present FlowMO: an open-source Python library for molecular property prediction with Gaussian Processes. Built upon GPflow and RDKit, FlowMO enables the user to make predictions with well-calibrated uncertainty estimates, an output central to active learning and molecular design applications. Gaussian Processes are particularly attractive for modelling small molecular datasets, a characteristic of many real-world virtual screening campaigns where high-quality experimental data is scarce. Computational experiments across three small datasets demonstrate comparable predictive performance to deep learning methods but with superior uncertainty calibration.
@article{2020_Moss, title = {Gaussian Process Molecule Property Prediction with {FlowMO}}, author = {Griffiths, Ryan-Rhys and Moss, Henry B}, journal = {arXiv preprint arXiv:2010.01118}, year = {2020}, dimensions = {true}, url = {https://arxiv.org/abs/2010.01118}, } -
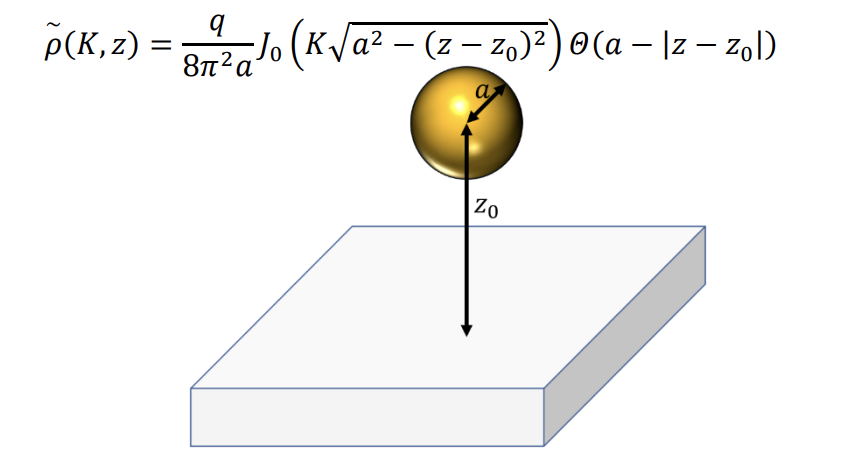 On the Voltage-Controlled Assembly of Nanoparticle Arrays at Electrochemical Solid/Liquid InterfacesCristian Zagar, Ryan-Rhys Griffiths, Rudolf Podgornik, and 1 more authorJournal of Electroanalytical Chemistry, 2020
On the Voltage-Controlled Assembly of Nanoparticle Arrays at Electrochemical Solid/Liquid InterfacesCristian Zagar, Ryan-Rhys Griffiths, Rudolf Podgornik, and 1 more authorJournal of Electroanalytical Chemistry, 2020Research in the field of nanoplasmonic metamaterials is moving towards more and more interesting and, potentially useful, applications. In this paper we focus on a class of such metamaterials formed by voltage controlled self-assembly of metallic nanoparticale at electrochemical solid |liquid interfaces. We perform a simplified, comprehensive analysis of the stability of a nanoparticle arrays under different conditions and assembly. From the Poisson-Boltzmann model of electrostatic interactions between a metallic nanoparticle and the electrode and between the nanoparticles at the electrode, as well as the Hamaker-Lifshitz theory of the corresponding van der Waals interactions, we reach some conclusions regarding the possibility to build arrays of charged nanoparticles on electrodes and disassemble them, subject to variation of applied voltage. Since systems of this type have been shown, recently, to provide nontrivial electrotuneable optical response, such analysis is crucial for answering the question whether the scenarios of electrochemical plasmonics are feasible.
@article{2020_Zagar, title = {On the Voltage-Controlled Assembly of Nanoparticle Arrays at Electrochemical Solid/Liquid Interfaces}, author = {Zagar, Cristian and Griffiths, Ryan-Rhys and Podgornik, Rudolf and Kornyshev, Alexei A}, journal = {Journal of Electroanalytical Chemistry}, volume = {872}, pages = {114275}, year = {2020}, publisher = {Elsevier}, doi = {10.1016/j.jelechem.2020.114275}, url = {https://www.sciencedirect.com/science/article/abs/pii/S1572665720305038}, dimensions = {true}, }
2019
-
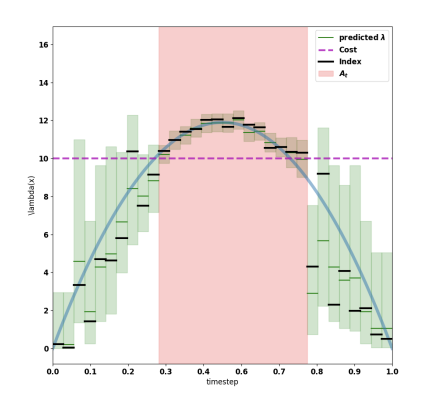 Adaptive Sensor Placement for Continuous SpacesJames Grant, Alexis Boukouvalas, Ryan-Rhys Griffiths, and 3 more authorsIn International Conference on Machine Learning, 2019
Adaptive Sensor Placement for Continuous SpacesJames Grant, Alexis Boukouvalas, Ryan-Rhys Griffiths, and 3 more authorsIn International Conference on Machine Learning, 2019We consider the problem of adaptively placing sensors along an interval to detect stochastically-generated events. We present a new formulation of the problem as a continuum-armed bandit problem with feedback in the form of partial observations of realisations of an inhomogeneous Poisson process. We design a solution method by combining Thompson sampling with nonparametric inference via increasingly granular Bayesian histograms and derive an \tildeO(T^2/3) bound on the Bayesian regret in T rounds. This is coupled with the design of an efficent optimisation approach to select actions in polynomial time. In simulations we demonstrate our approach to have substantially lower and less variable regret than competitor algorithms.
@inproceedings{2019_Grant, title = {Adaptive Sensor Placement for Continuous Spaces}, author = {Grant, James and Boukouvalas, Alexis and Griffiths, Ryan-Rhys and Leslie, David and Vakili, Sattar and De Cote, Enrique Munoz}, booktitle = {International Conference on Machine Learning}, pages = {2385--2393}, year = {2019}, organization = {PMLR}, dimensions = {true}, url = {https://proceedings.mlr.press/v97/grant19a.html}, }
2017
-
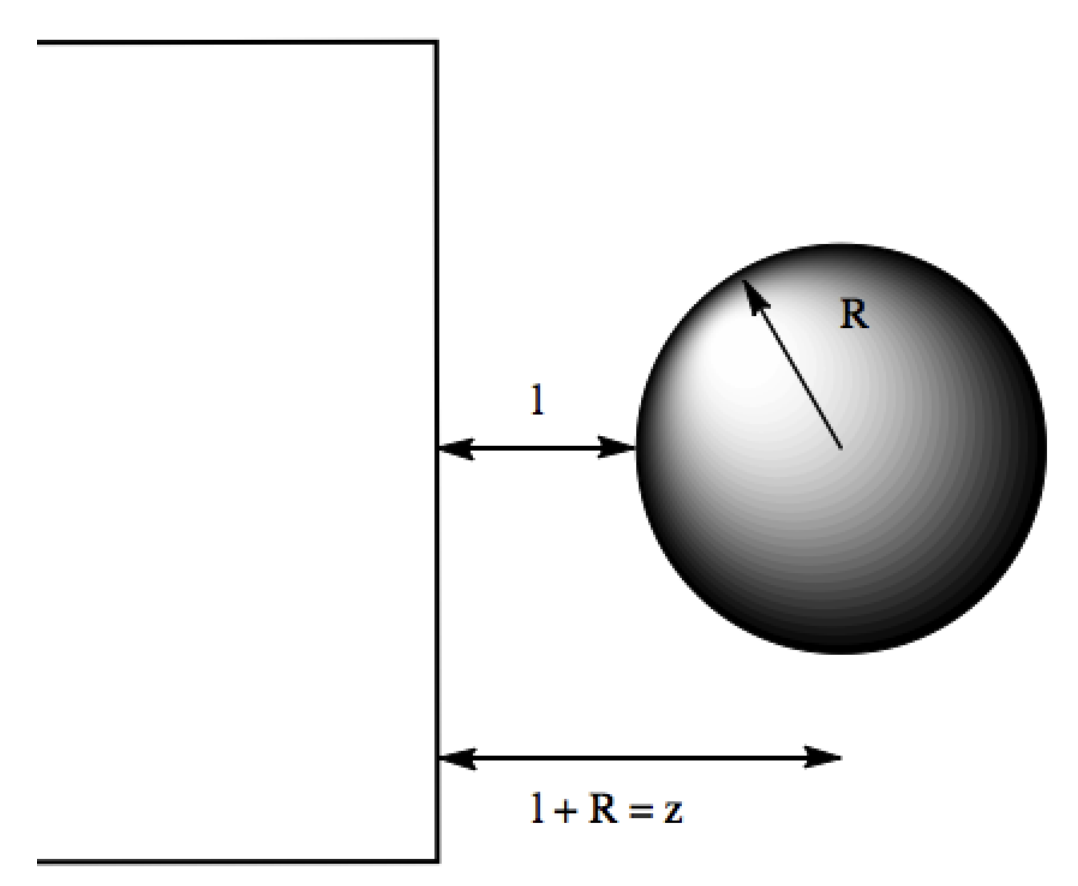 A Theory of a Self-Assembling Electrovariable Smart MirrorRyan-Rhys GriffithsarXiv preprint arXiv:1709.05494, 2017
A Theory of a Self-Assembling Electrovariable Smart MirrorRyan-Rhys GriffithsarXiv preprint arXiv:1709.05494, 2017A theory describing the forces governing the self-assembly of nanoparticles at the solid-liquid interface is developed. In the process, new theoretical results are derived to describe the effect that the field penetration of a point-like particle, into an electrode, has on the image potential energy, and pair interaction energy profiles at the electrode-electrolyte interface. The application of the theory is demonstrated for gold and ITO electrode systems, promising materials for novel colour-tuneable electrovariable smart mirrors and mirror-window devices respectively. Model estimates suggest that electrovariability is attainable in both systems and will act as a guide for future experiments. Lastly, the generalisability of the theory towards electrovariable, nanoplasmonic systems suggests that it may contribute towards the design of intelligent metamaterials with programmable properties.
@article{2017_Griffiths, title = {A Theory of a Self-Assembling Electrovariable Smart Mirror}, author = {Griffiths, Ryan-Rhys}, journal = {arXiv preprint arXiv:1709.05494}, dimensions = {true}, year = {2017}, url = {https://arxiv.org/abs/1709.05494}, }